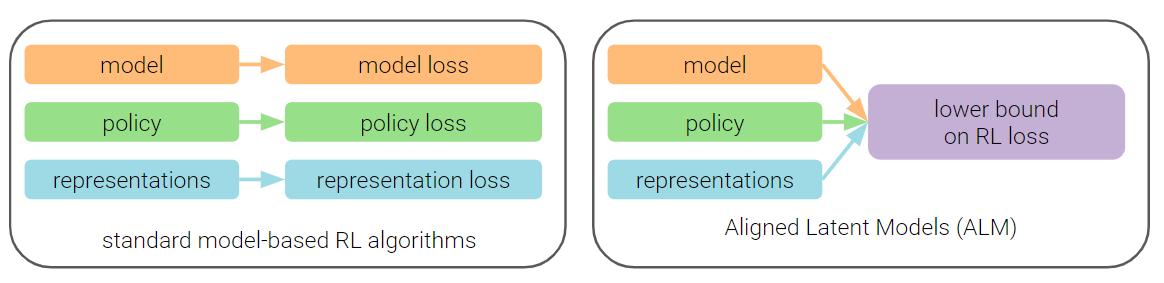
While reinforcement learning (RL) methods that learn an internal model of the environment have the potential to be more sample efficient than their model-free counterparts, learning to model raw observations from a high dimensional sensors can be challenging. To address this, prior work has instead learned low-dimensional representation of observations, through auxiliary objectives like reconstruction or value prediction, where their precise alignment with the RL objective often remains unclear. In this work, we propose a single objective for jointly optimizing these representations together with a model and a policy and show that this is an evidence lower bound on expected returns.
Unlike prior bounds for model-based RL on policy exploration or model guarantees, our bound is directly on the overall RL objective. Empirically, we demonstrate that the resulting algorithm from this lower bound matches, if not improves the sample-efficiency of prior model-based and model-free RL methods. Importantly, while prior model-based methods typically come at the cost of high computation demands, our method is only 4 times slower than model-free SAC and trains at ~ 48 batches / sec on a single GPU.
Videos of agents trained using ALM on Humanoid-v2, Ant-v2, and Walker2d-v2 using limited data (300K env steps).